Hierarchical Model Builder
Introduction
The Hierarchical Model Builder is used to create Model Selector models which can be used to perform decision tree operations. These models are used for applications like:
- Local Regression Models: Badly non-linear data, or data which contains separate "domains" may require models which are specific to the each of the different sub-domains in the data (For example, when different solvents or operation conditions each require a specific "local" model to achieve the necessary accuracy.) A hierarchical model can be used to first determine which sub-domain you are in, then apply the appropriate local model.
- Classification Decision Trees: Complicated classification problems often can not be solved using a single classification model (PLSDA, SVM, SIMCA) but instead require the problem to be broken down into sub-groups with individual models handling the increased detail of the problem. A hierarchical model might start by selecting between general categories, then sub-models (possibly including additional hierarchical models) would sub-divide those general categories using increasingly specific classification models.
- Input and Output Filtering: In some cases, prior to applying a model, the input data should be tested for appropriate conditioning (e.g. insufficient signal or an "invalid data" flag variable being set). In others, the output of a model should be tested for being outside appropriate limits before returning the result. Hierarchical models can be used to first test the raw input data for specific conditions or to test the output of a regression, classification, or projection (PCA, PARAFAC, etc.) model.
Hierarchical Model Builder Interface
The Hierarchical Model Builder interface comprises a set of toolbar buttons, a set of node tools containing different nodes used to build a model, a model canvas on which the hierarchical model is built, and a Model Cache pane from which models and data can be added to the hierarchical model canvas.

The model canvas is read from left to right. Data is first passed through the root (left-most) rule node and the results from that decision node are used to select one of the branches to the immediate right of the root node. Each of these branches can either be an "end point" node, defining what output should be given for the corresponding condition, or another decision rule node, with additional branches to its right.
To begin defining a hierarchical model, a root rule node must be defined by either dragging a model from the Model Cache pane onto the root (left-most) decision node or by choosing to use a variable-based rule as described in the Rule Node description below.
Introduction to Node Types
Hierarchical models are built from one or more rules (decision nodes) plus end nodes for each condition tested by the rule nodes. Rule nodes decide which of the branches underneath it should be selected. End nodes are at the ends of each branch and define what should be returned as a "prediction" for any sample that arrives at the end of that branch.
Rule Nodes
Rule nodes (also known as decision nodes) can be one of several types depending on what is being tested to decide which branch to follow:
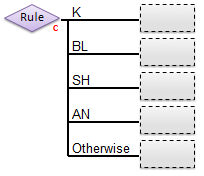
- Classification Test-Based Rule - chooses a branch based on the class predicted by a classification model (PLSDA, KNN, SIMCA, SVMDA) from the input data. The number of branches of a node of this type is defined by the number of classes defined in the classification model. There will be one branch for each class defined, plus one branch which is used if none of the classes are selected.

- The following is an example of a classification model-based rule before end-points have been assigned. The given model had four classes defined (K, BL, SH, AN) plus the additional "otherwise" branch used if none of the other classes is selected.

- Variable Test-Based Rule - chooses a branch based on the state of the raw input data (rather than outputs of models.) Each branch is given a test condition that defines: a variable to test, a comparison operator, and a value to compare to. Variables to test can be defined using either a string (in double-quotes, e.g. "Toggle_A") which will select the variable of the raw data that has a matching label or an axisscale (given as a value inside square brackets, e.g. [123.4] )

- The Test Condition for each branch is defined by clicking on the end-point and entering a valid string into the Test Condition property for the branch. Test conditions are evaluated sequentially, so the first branch test condition that is met is selected, even if a subsequent branch's test condition would also be met. For more information, see Test Conditions below.
- Regression or Projection Test-Based Rule - chooses a branch based on the predictions of the given (non-classification) model from the input data. Any model type that outputs a DataSet object or a standard prediction including, but not limited to regression models (PLS, PCR, MLR, CLS), decomposition models (PCA, MCR, PARAFAC), or other "transformation" models (trendtool).


- Like with Variable Test-Based Rules, Regression and Projection Test-Based rules also require a Test Condition string. These rules consist of a prediction selector (saying which predicted y-value or which component score should be tested), a comparison operator, and a value to compare to. For more information, see Test Conditions below.